Haute disponibilité Galera MariaDB et Redis Sentinel sur trois nœuds

Ça fait quelques temps que je suis frustré parce que je connais que dal à redis et encore moins à redis sentinel. Vu que ça fait partie des technos que je peux rencontrer en Maintient en Conditions Opérationnelles, on va dire que ça me met un peu mal à l’aise.
Alors que je lisais un excellent article de Julien MOROT au sujet de KeepAlived, en cliquant sur le nom de son auteur, je tombe non pas sur une pépite mais sur deux qui, dans le cadre d’un lab, vont plutôt bien ensemble.
Tu l’auras compris, je réclame aucune paternité sur le sujet que je vais aborder et je t’invite à lire ce que Monsieur MOROT a écrit sur ces sujets plutôt que la suite de cet article parce qu’en plus d’écrire des trucs intéressant, il a une super plume. Je vais tenter d’agréger de-ci de-là quelques autres détails sur redis et de rendre ça intéressant en te rendant compte ici de mon retour d’expérience. Si tu lis cet article, c’est que le Monsieur mentionné ci-dessus nous aura défriché le terrain à merveille.
Comme dans le premier lab de haute dispo, on a une mission hyper importante : héberger un blog wordpress. C’est palpitant non ? Ouais, désolé une it works page de nginx moi ça me suffit pas.
Pour ça on va utiliser deux serveurs haproxy, un serveur apache parce que j’ai la flemme d’en monter deux (mais configuré pour prévoir l’évolution) et qu’on a déjà vu ça ensemble précédemment mais surtout : trois serveurs SBGD Galera MariaDB et redis sentinel (dans la vraie vie, toi tu sépareras probablement sur des machines différentes ; faut se donner les moyens si t’as besoin de ce genre d’archi). Pareil ! On a déjà monté des vm ensemble (si c’est pas l’cas : abonne-toi, commente et active la cloche) alors je vais pousser les sliders de la fainéantise à leurs paroxysmes en utilisant des conteneurs lxc Debian 12 sur lesquels je vais juste me configurer vim. Espérons que ça fonctionne…
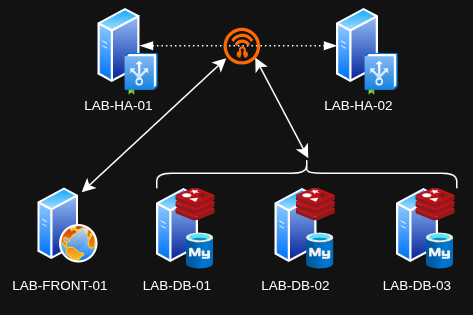
| ID | Hôte | Adresse IP |
| 701 | LAB-HA-01 | 10.0.0.101 |
| 702 | LAB-HA-02 | 10.0.0.102 |
| 703 | LAB-FRONT-01 | 10.0.0.103 |
| 704 | LAB-DB-01 | 10.0.0.104 |
| 705 | LAB-DB-02 | 10.0.0.105 |
| 706 | LAB-DB-03 | 10.0.0.106 |
| na | vip | 10.0.0.107 |
Bien entendu, je commence mon lab avec un apt update && apt upgrade sur l’ensemble des machines (avec un cluster dans Asbrù CM c’est vite vu).
Montage du de LB HAProxy avec VIP Keepalived
On installe haproxy, keepalived et, whois (pour avoir mkpasswd) et on autorise les dummy interfaces pour permettre l’usage des IP virtuelles.
root@LAB-HA-01:~# apt install haproxy keepalived whois
root@LAB-HA-01:~# cat > /etc/sysctl.d/99-keepalived.conf << EOF
net.ipv4.ip_nonlocal_bind = 1
EOF
root@LAB-HA-01:~# sysctl -p /etc/sysctl.d/99-keepalived.conf
net.ipv4.ip_nonlocal_bind = 1
root@LAB-HA-01:~# mkpasswd -m sha-256 haproxy
$5$zBqt5F3.idx4w8ZX$wOUOH40rzbRMSpqm3Wcz/hzHPZdSt2nlXdnOEJT6iE4Configuration de base de haproxy
Et on entame la configuration de haproxy en ajoutant la page de statistiques.
# [...]
listen stats
bind 0.0.0.0:12345
mode http
maxconn 10
stats enable
stats refresh 20s
stats show-legends
stats show-node
stats hide-version
stats uri /
acl is_auth http_auth(stats)
acl is_admin http_auth_group(stats) stats-admin
stats http-request auth unless is_auth
stats admin if is_admin
timeout client 100s
timeout server 100s
timeout connect 100s
timeout queue 100s
userlist stats
user haproxy password $5$zBqt5F3.idx4w8ZX$wOUOH40rzbRMSpqm3Wcz/hzHPZdSt2nlXdnOEJT6iE4 groups stats-admin
group stats-adminJe vérifie ma configuration haproxy mais je le restart pas parce que pour l’instant il ne sert pas à grand chose.
root@LAB-HA-01:~# haproxy -c -f /etc/haproxy/haproxy.cfg
Configuration file is validConfiguration de keepalived
Je reprend ma configuration de 2024 que j’adapte (elle y est commentée) même si je te rappelle que le paquet fournit un fichier d’exemple intéressant.
root@LAB-HA-01:~# cat /etc/keepalived/keepalived.conf.sample! Configuration File for keepalived
global_defs {
vrrp_no_swap
vrrp_garp_master_delay 10
vrrp_garp_master_refresh 60
vrrp_garp_interval 0.001
}
vrrp_instance labhadb-lb-vip {
state MASTER
interface eth0
virtual_router_id 1
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 8_Caract # eres_max
}
virtual_ipaddress {
10.0.0.107
}
unicast_src_ip 10.0.0.101
unicast_peer {
10.0.0.102
}
}Tu arrêtes d’un côté, tu vérifies que la vip bascule bien. Tu rallumes, tu restart de l’autre et tu vérifies que ça repasse bien en configuration nominale.
root@LAB-HA-01:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eth0@if41: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether bc:24:11:d4:38:4b brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.0.101/24 brd 10.0.0.255 scope global eth0
valid_lft forever preferred_lft forever
inet 10.0.0.107/32 scope global eth0 <<< Ma VIP est ici
valid_lft forever preferred_lft forever
inet6 fe80::be24:11ff:fed4:384b/64 scope link
valid_lft forever preferred_lft foreverMontage de LAB-FRONT-01
Installation du serveur web
On va commencer par le plus rapide, le montage d’apache et le déploiement de wordpress.
root@LAB-FRONT-01:~# apt purge nano && apt install curl lsb-release ca-certificates gnupg2
# On suit la doc de Sury
root@LAB-FRONT-01:~# curl -sSLo /tmp/debsuryorg-archive-keyring.deb https://packages.sury.org/debsuryorg-archive-keyring.deb
root@LAB-FRONT-01:~# dpkg -i /tmp/debsuryorg-archive-keyring.deb
root@LAB-FRONT-01:~# sh -c 'echo "deb [signed-by=/usr/share/keyrings/debsuryorg-archive-keyring.gpg] https://packages.sury.org/php/ $(lsb_release -sc) main" > /etc/apt/sources.list.d/php.list'
root@LAB-FRONT-01:~# apt-get update
# Et on installe Apache2 et PHP sans oublier le module MySQL de PHP !
root@LAB-FRONT-01:~# apt install apache2 php8.3 php8.3-mysqlSous Debian le module php est déjà activé dans apache. Du coup, il me reste juste à déposer le code de wordpress dans son dossier, lui donner les bons droits et, lui faire un vhost.
# T'oublis pas que tu devrais pas utiliser le tld ".lab" !
root@LAB-FRONT-01:~# mkdir /var/www/labhadb.lab
root@LAB-FRONT-01:~# wget -qO- https://wordpress.org/latest.tar.gz | tar xvz --strip-components=1 -C /var/www/labhadb.lab/
wordpress/index.php
wordpress/license.txt
wordpress/readme.html
wordpress/wp-activate.php
# ...
root@LAB-FRONT-01:~# chown -R www-data:www-data /var/www/labhadb.lab
root@LAB-FRONT-01:~# vi /etc/apache2/sites-available/labhadb.lab.conf<VirtualHost *:80>
ServerName labhadb.lab
# Indexes, root directory
DirectoryIndex index.php index.html
DocumentRoot /var/www/labhadb.lab/
# Logs
ErrorLog /var/log/apache2/error_labhadb.lab_log
CustomLog /var/log/apache2/access_labhadb.lab_log combined
Options FollowSymLinks
</VirtualHost>root@LAB-FRONT-01:~# a2ensite labhadb.lab.conf
root@LAB-FRONT-01:~# systemctl reload apache2Allons informer haproxy de la présence de notre serveur web.
Renseigner le service web dans haproxy
J’ajoute mon frontend et mon backend dans haproxy.
#[...]
frontend frontlabhadb
bind 10.0.0.107:80
mode http
default_backend frontservers
option httplog
backend frontservers
balance roundrobin
option httpchk
http-check connect
mode http
server lab-front-01 10.0.0.103:80 check
Pour aller plus loin, j’ai besoin de la base de données.
Montage du cluster MariaDB
Installation et configuration de Maria et Galera
C’est parti, nouveau cluster dans Asbrù CM pour installer MariaDB-Server sur les trois serveurs SGBD et, faire écouter MariaDB sur toutes les interfaces. galera-4 étant installé en même temps que MariaDB, pas besoin de l’installer.
# Oublis pas ! Ces opérations sont réalisées sur les trois serveurs.
root@LAB-DB-01:~# apt install mariadb-server
root@LAB-DB-01:~# sed -i 's/^bind-address.*/bind-address = 0.0.0.0/g' /etc/mysql/mariadb.conf.d/50-server.cnf
root@LAB-DB-01:~# systemctl restart mariadbJe sais pas si c’est une différence entre Ubuntu et Debian mais j’ai eu quelques difficultés. D’une part le dossier /var/log/mysql/ n’était pas créé par l’installation et surtout il a fallu donner les droits à mysql d’aller y écrire.
# Oublis pas ! Ces opérations sont réalisées sur les trois serveurs.
root@LAB-DB-01:~# mkdir /var/log/mysql
root@LAB-DB-01:~# chmod 774 /var/log/mysql
root@LAB-DB-01:~# chown root:mysql /var/log/mysqlJe configure alors le cluster avec le SGBD éteint. wsrep_on est en charge de l’activation de la réplication et wsrep_cluster_address recense les serveurs membres. Là aussi, j’ai rencontré une difficulté : sans renseigner wsrep_provider, mes MariaDB restaient en standalone (avant ça j’avais testé l’ajout de wsrep_node_name et de wsrep_node_address sans succès). Ahumm, l’article est de Mai 2023 et je trouve une source qui déjà en 2014 indiquait cette variable comme obligatoire.
# Oublis pas ! Ces opérations sont réalisées sur les trois serveurs.
root@LAB-DB-01:~# systemctl stop mariadb
root@LAB-DB-01:~# cat <<EOF > /etc/mysql/mariadb.conf.d/60-galera.cnf
[galera]
wsrep_on = ON
wsrep_provider = /usr/lib/galera/libgalera_smm.so
wsrep_cluster_name = "MariaDB Galera Cluster"
wsrep_cluster_address = gcomm://10.0.0.104,10.0.0.105,10.0.0.106
binlog_format = row
default_storage_engine = InnoDB
bind-address = 0.0.0.0
wsrep_slave_threads = 4
innodb_flush_log_at_trx_commit = 1
log_error = /var/log/mysql/error-galera.log
EOFJe voulais pas juste recopier bêtement les dires de J. MOROT donc j’ai vérifié pour toi : Oui, la recommandation de MariaDB est bien de paramétrer wsrep_slave_threads au double du nombre de CPU et puis log_error, log_error… ils auraient dû appeler ça debug_log plutôt parce que ça ne pond pas que de l’erreur ce log.
A partir d’ici, on n’utilisera plus le cluster Asbrù CM pour n’agir que sur une machine à la fois. J’initialise alors le Primary Component en initialisant le cluster.
root@LAB-DB-01:~# galera_new_cluster
root@LAB-DB-01:~# which galera_new_cluster
/usr/bin/galera_new_cluster
root@LAB-DB-01:~# cat /usr/bin/galera_new_cluster
#!/bin/sh
# This file is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
if [ "${1}" = "-h" ] || [ "${1}" = "--help" ]; then
cat <<EOF
Usage: ${0}
The script galera_new_cluster is used to bootstrap new Galera Cluster,
when all the nodes are down. Run galera_new_cluster on the first node only.
On the remaining nodes simply run 'service start'.
For more information on Galera Cluster configuration and usage see:
https://mariadb.com/kb/en/mariadb/getting-started-with-mariadb-galera-cluster/
EOF
exit 0
fi
systemctl set-environment _WSREP_NEW_CLUSTER='--wsrep-new-cluster' && \
systemctl restart ${1:-mariadb}
extcode=$?
systemctl set-environment _WSREP_NEW_CLUSTER=''
exit $extcodeTu l’auras vu, ce script manipule systemctl pour lancer MariaDB avec les paramètres du cluster. Du coup sur les autres nœuds, on le lance tout simplement…
# Nœud 2 :
root@LAB-DB-02:~# systemctl start mariadb
# Nœud 3 :
root@LAB-DB-03:~# systemctl start mariadbComme dans l’article originel, je retrouve bien le boostrap du cluster, les jonctions des serveurs membres dans le fichier de log.
2026-02-13 0:27:51 0 [Note] WSREP: Server initialized
2026-02-13 0:27:51 0 [Note] WSREP: Server status change initializing -> initialized
2026-02-13 0:27:51 2 [Note] WSREP: Bootstrapping a new cluster, setting initial position to 00000000-0000-0000-0000-000000000000:-1
2026-02-13 0:27:51 5 [Note] WSREP: Recovered cluster id 0388caff-0872-11f1-9770-27762bdd11a1
2026-02-13 0:27:51 2 [Note] WSREP: Server status change initialized -> joined2026-02-13 0:28:05 8 [Note] WSREP: ================================================
View:
id: 0388caff-0872-11f1-9770-27762bdd11a1:10
status: primary
protocol_version: 4
capabilities: MULTI-MASTER, CERTIFICATION, PARALLEL_APPLYING, REPLAY, ISOLATION, PAUSE, CAUSAL_READ, INCREMENTAL_WS, UNORDERED, PREORDERED, STREAMING, NBO
final: no
own_index: 0
members(3):
0: d4cafa26-0872-11f1-8d8f-f32cf68a7752, LAB-DB-01
1: d8d22f24-0872-11f1-a1f1-9220eb773353, LAB-DB-02
2: dc70fae5-0872-11f1-98e6-76bea1e84bcb, LAB-DB-03
=================================================
2026-02-13 0:28:05 8 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2026-02-13 0:28:05 8 [Note] WSREP: Lowest cert index boundary for CC from group: 10
2026-02-13 0:28:05 8 [Note] WSREP: Min available from gcache for CC from group: 1
2026-02-13 0:28:05 0 [Note] WSREP: Member 2.0 (LAB-DB-03) requested state transfer from '*any*'. Selected 1.0 (LAB-DB-02)(SYNCED) as donor.
2026-02-13 0:28:05 0 [Note] WSREP: 1.0 (LAB-DB-02): State transfer to 2.0 (LAB-DB-03) complete.
2026-02-13 0:28:05 0 [Note] WSREP: Member 1.0 (LAB-DB-02) synced with group.
2026-02-13 0:28:07 0 [Note] WSREP: 2.0 (LAB-DB-03): State transfer from 1.0 (LAB-DB-02) complete.
2026-02-13 0:28:07 0 [Note] WSREP: Member 2.0 (LAB-DB-03) synced with group.De la même manière, je peux vérifier que tout est ok directement dans la CLI mysql.
MariaDB [(none)]> show status like 'wsrep_ready';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wsrep_ready | ON |
+---------------+-------+
1 row in set (0.000 sec)
MariaDB [(none)]> show status like 'wsrep_connected';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| wsrep_connected | ON |
+-----------------+-------+
1 row in set (0.001 sec)
MariaDB [(none)]> show status like 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+
1 row in set (0.001 sec)
MariaDB [(none)]> show status like 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+
1 row in set (0.000 sec)C’est gentil sur le papier, on a trois serveurs master, maintenant faut aiguiller tout ça.
Gestion du load balancing MySQL dans HAProxy
Les checks effectués par haproxy nécessitent l’usage d’un compte utilisateur mysql valide. Tu créés alors un compte pour chaque LB depuis la cli mysql sur l’un des serveurs DB.
MariaDB [(none)]> CREATE USER 'haproxy'@'10.0.0.101';
Query OK, 0 rows affected (0.004 sec)
MariaDB [(none)]> CREATE USER 'haproxy'@'10.0.0.102';
Query OK, 0 rows affected (0.003 sec)J’ajoute mon frontend et mon backend dans haproxy.
# [...
frontend galera
bind 10.0.0.107:3306
mode tcp
option tcplog
default_backend galera_nodes
backend galera_nodes
balance leastconn
mode tcp
option tcpka
option mysql-check user haproxy
server lab-db-01 10.0.0.104:3306 check weight 1
server lab-db-02 10.0.0.105:3306 check weight 1
server lab-db-03 10.0.0.106:3306 check weight 1Si t’oublies de créer les comptes utilisateurs mysql, haproxy te le rappelleras.
root@LAB-HA-01:~# systemctl restart haproxy
Broadcast message from systemd-journald@LAB-HA-01 (Wed 2026-03-07 21:51:22 UTC):
haproxy[8384]: backend galera_nodes has no server available!Je vérifie la syntaxe de mon fichier, je redémarre haproxy sur les deux LB, je modifie mon fichier host et je devrais pouvoir setup wordpress mais il faut quand même créer une DB et un utilisateur avant
MariaDB [(none)]> CREATE DATABASE wordpress;
MariaDB [(none)]> CREATE USER "wordpress"@"%" IDENTIFIED BY "wppassword";
MariaDB [(none)]> GRANT ALL PRIVILEGES ON wordpress.* TO "wordpress"@"%";
MariaDB [(none)]> FLUSH PRIVILEGES;Je le dis pas souvent hein mais si tu utilises les mots de passe que je mets dans mes articles pour ta prod, arrête ton ordi et repasse au papier.
Bref, j’ouvre mon navigateur sur http://labhadb.lab et j’entre les informations ; la seule importante à retenir c’est bien d’utiliser la VIP pour l’hôte de base de données.
C’est le bon moment pour aller sur n’importe quel serveur MariaDB et vérifier la magie de la réplication (moi je suis allé sur LAB-DB-03) :
MariaDB [(none)]> SELECT user,host FROM mysql.user;
+-------------+------------+
| User | Host |
+-------------+------------+
| wordpress | % |
| haproxy | 10.0.0.101 |
| haproxy | 10.0.0.102 |
| mariadb.sys | localhost |
| mysql | localhost |
| root | localhost |
+-------------+------------+
6 rows in set (0.001 sec)
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| wordpress |
+--------------------+
5 rows in set (0.001 sec)C’est quand même chouette tout ça ! On peut passer à la suite.
Montage du cluster Redis Sentinel
Tout ce temps pour arriver au point qui m’intéressait initialement : redis !
Installation de Redis et paramétrage de la réplication
J’installe le paquet depuis les dépôts et je créé mes fichiers de configuration custom.
root@LAB-DB-01:~# apt install redis
root@LAB-DB-01:~# cat > /etc/redis/redis.conf << EOF
bind 0.0.0.0
supervised systemd
protected-mode yes
requirepass redispasswd
masterauth redispasswd
logfile "/var/log/redis/redis-server.log"
dir /var/lib/redis
# Sauvegarde si 1 clé modifiée en 15 min
save 900 1
# Sauvegarde si 10 clés modifiées en 5 min
save 300 10
# Sauvegarde si 10 000 clés modifiées en 1 min
save 60 10000
# Limite mémoire Redis
maxmemory 1024mb
# LFU : éviction par fréquence d'accès
maxmemory-policy allkeys-lfu
EOF
root@LAB-DB-01:~# systemctl restart redisJ’initialise alors la réplication sur les nœuds 02 et 03 puis, je vérifie le bon fonctionnement.
root@LAB-DB-02:~# redis-cli -a redispasswd replicaof 10.0.0.104 6379
root@LAB-DB-02:~# redis-cli
127.0.0.1:6379> auth redispasswd
OK
127.0.0.1:6379> INFO replication
# Replication
role:slave
master_host:10.0.0.104
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_read_repl_offset:56
slave_repl_offset:56
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:9273e2d606d19c087e29c22ec9cf27333b7e162f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:56
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:56
En prod, j’aurai évité de mettre le mot de passe via -a pour éviter qu’il traîne dans l’historique.
root@LAB-DB-03:~# redis-cli
127.0.0.1:6379> AUTH redispasswd
OK
127.0.0.1:6379> replicaof 10.0.0.105 6379
OKInstallation et paramétrage de Redis-Sentinel
L’installation se fait depuis les dépôts et on mixe la configuration proposée dans l’article source et celle du fichier de conf originel.
root@LAB-DB-01:~# apt install redis-sentinel
root@LAB-DB-01:~# mv /etc/redis/sentinel.conf /etc/redis/sentinel.conf.sample
root@LAB-DB-01:~# cat > /etc/redis/sentinel.conf << EOF
bind 0.0.0.0
port 26379
supervised systemd
protected-mode no
logfile "/var/log/redis/redis-sentinel.log"
dir "/var/lib/redis"
requirepass "redispasswd"
sentinel sentinel-pass redispasswd
sentinel auth-pass mymaster redispasswd
sentinel monitor mymaster 10.0.0.104 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
EOFSentinel n’est pas très content, il ne peut pas écrire dans /etc/redis/sentinel.conf parce que je l’ai écrasé comme un malpropre. Sinon après ça, tout semble fonctionner correctement.
root@LAB-DB-01:~# chown redis:redis /etc/redis/sentinel.conf
root@LAB-DB-01:~# systemctl restart redis-sentinel
root@LAB-DB-01:~# redis-cli -p 26379
127.0.0.1:26379> auth redispasswd
OK
127.0.0.1:26379> info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_tilt_since_seconds:-1
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=10.0.0.104:6379,slaves=2,sentinels=1
127.0.0.1:26379> sentinel slaves mymaster
1) 1) "name"
2) "10.0.0.106:6379"
3) "ip"
4) "10.0.0.106"
5) "port"
6) "6379"
# [...]
2) 1) "name"
2) "10.0.0.105:6379"
3) "ip"
4) "10.0.0.105"
5) "port"
6) "6379"
# [...]Paramétrage de Redis dans WordPress
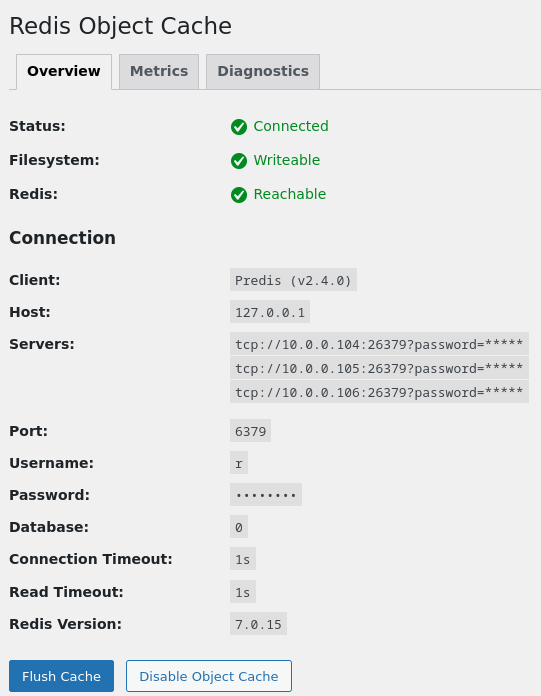
Avant tout j’ai bêtement installé le plugin WordPress Redis Object Cache. J’ai même vu que le plugin était compatible Sentinel, quelle aubaine ! J’ai donc appliqué la configuration dans mon wp-config.php.
/* Add any custom values between this line and the "stop editing" line. */
define('WP_REDIS_CLIENT', 'predis');
define('WP_REDIS_SENTINEL', 'mymaster');
define('WP_REDIS_SERVERS', [
'tcp://10.0.0.104:26379?password=redispasswd', // lab-db-01
'tcp://10.0.0.105:26379?password=redispasswd', // lab-db-02
'tcp://10.0.0.106:26379?password=redispasswd', // lab-db-03
]);
define( 'WP_REDIS_DATABASE', 0 );
define( 'WP_REDIS_TIMEOUT', 1 );
define( 'WP_REDIS_READ_TIMEOUT', 1 );
define( 'WP_REDIS_PASSWORD', 'redispasswd' );
/* That's all, stop editing! Happy publishing. */Pour finir, j’ai activé Redis dans Worpdress.
Conclusion
La partie sentinel m’a donné pas mal de fil à retordre. Ne connaissant pas le produit et décidant de forger un fichier de conf plutôt que de (lire…) modifier le fichier originel, je me suis créé de nombreux problèmes ridicules (oubli du dir, ou du logfile ; mot de passe différent sur les serveurs).
En faisant quelques tests de bascule, de perte du master j’ai aussi constaté que les délais utilisés ici sont également un peu longs. Lorsque le master n’est plus joignable, WordPress renvoi un HTTP/500 le temps que le quorum en élise un nouveau.
De même, j’ai constaté que sentinel conservait le master après le retour d’un nœud perdu. On peut adapter le comportement en jouant sur les priorités (root@LAB-DB-01:~# redis-cli -h 10.0.0.104 -p 6379 -a redispasswd CONFIG SET replica-priority 1) avant de lancer un failover.
# root@LAB-DB-01:~# systemctl stop redis-server
... # +sdown master mymaster 10.0.0.104 6379
... * Sentinel new configuration saved on disk
... # +new-epoch 6
... * Sentinel new configuration saved on disk
... # +vote-for-leader 2d4ccbbe66bb88ef961ce5b08aeace690d4257d5 6
... # +odown master mymaster 10.0.0.104 6379 #quorum 3/2
... # Next failover delay: I will not start a failover before Fri Mar 6 22:16:20 2026
... # +config-update-from sentinel 2d4ccbbe66bb88ef961ce5b08aeace690d4257d5 10.0.0.104 26379 @ mymaster 10.0.0.104 6379
... # +switch-master mymaster 10.0.0.104 6379 10.0.0.106 6379
... * +slave slave 10.0.0.105:6379 10.0.0.105 6379 @ mymaster 10.0.0.106 6379
... * +slave slave 10.0.0.104:6379 10.0.0.104 6379 @ mymaster 10.0.0.106 6379
... * Sentinel new configuration saved on disk
# root@LAB-DB-01:~# systemctl start redis-server
... * +convert-to-slave slave 10.0.0.104:6379 10.0.0.104 6379 @ mymaster 10.0.0.106 6379
# root@LAB-DB-01:~# redis-cli -h 10.0.0.104 -p 26379 -a redispasswd SENTINEL FAILOVER mymaster
# OK
... * Sentinel new configuration saved on disk
... # +new-epoch 7
... # +config-update-from sentinel 2d4ccbbe66bb88ef961ce5b08aeace690d4257d5 10.0.0.104 26379 @ mymaster 10.0.0.106 6379
... # +switch-master mymaster 10.0.0.106 6379 10.0.0.104 6379
... * +slave slave 10.0.0.105:6379 10.0.0.105 6379 @ mymaster 10.0.0.104 6379
... * +slave slave 10.0.0.106:6379 10.0.0.106 6379 @ mymaster 10.0.0.104 6379
... * Sentinel new configuration saved on diskInformations complémentaires
Dans la CLI Redis, j’ai gardé en mémoire certaines commandes :
AUTH password: pour s’authentifier,KEYS '[wp:]*': pour lister les clés en mémoire,DBSIZE: pour connaitre le nombre de clés en mémoire,INFO [noun]: pour connaître l’état de Redis,SAVE: pour lancer un backup manuellement,GET "key name": pour afficher la valeur associée à une clé,redis-cli -n [0-16]: pour ouvrir la CLI sur une base de données en particulier.
En prod, il conviendra d’éviter la présence des mots de passe dans l’historique donc on préférera gérer différemment la manière dont on s’authentifie si on souhaite exécuter des commandes sans entrer dans la CLI. On pourra par exemple exporter la variable REDISCLI_AUTH
root@LAB-DB-01:~# redis-cli info
NOAUTH Authentication required.
root@LAB-DB-01:~# read -s REDISCLI_AUTH && export REDISCLI_AUTH
root@LAB-DB-01:~# redis-cli info server
# Server
redis_version:7.0.15
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:5281cccdf7ef82d6
redis_mode:standalone
os:Linux 6.14.11-4-pve x86_64
arch_bits:64
monotonic_clock:POSIX clock_gettime
multiplexing_api:epoll
atomicvar_api:c11-builtin
gcc_version:12.2.0
process_id:1998
process_supervised:systemd
run_id:ffc6b928d3399d902144a9641ba591a19f066e0b
tcp_port:6379
server_time_usec:1772844782217937
uptime_in_seconds:9735
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:11237102
executable:/usr/bin/redis-server
config_file:/etc/redis/redis.conf
io_threads_active:0